
정답:
③ E-R 다이어그램은 개념적 설계 단계에서 사용되기 때문에 논리적 설계 단계에서 수행하는 작업이 아니다
개념설명
데이터베이스 설계 과정 (Database Design Process)
데이터베이스를 설계하는 과정은 다섯 가지 단계로 나뉜다.
| ① 요구사항 분석 | 사용자의 요구사항을 분석하여 데이터와 기능을 정의 |
| ② 개념적 설계 (Conceptual Design) | E-R 다이어그램을 이용해 데이터 모델링 수행 |
| ③ 논리적 설계 (Logical Design) | 관계형 데이터 모델을 기반으로 논리적 스키마 생성 |
| ④ 물리적 설계 (Physical Design) | 저장 구조, 인덱스, 성능 최적화를 고려한 설계 |
| ⑤ 구현 및 유지보수 | 실제 DBMS에 적용하고 유지보수 수행 |

.
정답:
③번: E1(KA1, A2), E2(KA2, A3), E21(KA2, A4), R(KA1, KA2)
개념설명
E-R 다이어그램을 관계형 데이터베이스로 변환하는 원칙
- 개체(Entity) → 릴레이션(Table)로 변환
- 개체 E1 → E1(KA1, A2)
- 개체 E2 → E2(KA2, A3)
- 다중값 속성(Multivalued Attribute) → 별도 테이블 생성
- 속성 A4는 E2에 종속되므로 별도 릴레이션 E21(KA2, A4)로 변환
- 다대다(M:N) 관계 → 별도 릴레이션 생성
- E1과 E2의 관계 R이 다대다(M:N) 관계이므로, 이를 위한 릴레이션 R(KA1, KA2)를 생성해야 함.

정답:
② 저장 데이터 관리자는 DBMS에서 디스크에 저장된 데이터와 시스템 카탈로그를 직접 관리함
개념설명
① 질의어 처리기(Query Processor) → ❌
- 사용자의 SQL 질의를 해석하고 실행 계획을 수립하는 역할.
- 하지만 디스크에 직접 접근하는 역할은 하지 않음.
③ 트랜잭션 관리자(Transaction Manager) → ❌
- 데이터 일관성과 무결성을 유지하며, 트랜잭션을 제어하는 역할을 담당.
- 하지만 직접적인 디스크 데이터 접근보다는 트랜잭션의 원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability, ACID)을 보장하는 역할.
- 디스크 입출력을 직접 제어하지 않음.
④ 런타임 데이터베이스 처리기(Runtime Database Processor) → ❌
- 사용자의 SQL 명령을 실행하고, 저장 데이터 관리자 및 트랜잭션 관리자와 상호 작용하는 역할.
- 그러나 실제 디스크 접근은 저장 데이터 관리자가 수행함.

정답:
④ 운영 데이터(Operational Data)
개념설명
① 공유 데이터(Shared Data) → ❌
- 데이터베이스는 여러 사용자와 시스템이 데이터를 공유할 수 있는 특성을 가짐.
- 하지만, 공유 데이터 자체가 운영을 수행하는 데 필수적인 것은 아님.
- 데이터가 공유되는 것은 데이터베이스의 특성 중 하나일 뿐, 조직의 운영을 위해 꼭 유지해야 하는 데이터 유형은 아님.
② 통합 데이터(Integrated Data) → ❌
- 통합 데이터는 중복을 최소화하고 여러 데이터가 논리적으로 통합된 데이터를 의미.
- 데이터베이스의 중요한 개념이지만, 운영을 수행하기 위해 꼭 필요한 데이터 유형을 의미하지는 않음.
③ 저장 데이터(Stored Data) → ❌
- 데이터베이스에 저장된 데이터라는 의미로, 단순히 저장된 데이터 자체를 의미할 뿐, 운영에 반드시 필요한 데이터라는 뜻은 아님.
④ 운영 데이터(Operational Data) → ✅
- 운영 데이터는 조직이 업무를 수행하는 데 필수적인 데이터를 의미.
- 예를 들어, 은행이라면 고객 계좌 정보, 거래 내역, 대출 기록 등이 운영 데이터가 됨.
- 기업에서는 재고 관리 데이터, 직원 정보, 회계 데이터 등이 이에 해당.
- 운영 데이터가 없으면 조직의 업무 수행이 불가능하므로, 반드시 유지해야 하는 데이터!

정답:
③ 내부 스키마를 수정하더라도 개념 스키마에 영향을 미치지 않는다.
개념설명
① 데이터베이스의 논리적 구조가 변경될 때 필요하다. → ✅
- 논리적 데이터 독립성은 개념 스키마(논리적 구조)가 변경되더라도 외부 스키마(사용자 인터페이스)에 영향을 주지 않도록 하는 것을 의미함.
② 외부 스키마와 개념 스키마 간의 사상(mapping)에 의해 제공된다. → ✅
- 외부 스키마(사용자가 보는 데이터)와 개념 스키마(데이터베이스 전체 구조) 간의 **사상(mapping)**을 통해 논리적 독립성을 제공함.
- 즉, 개념 스키마가 바뀌어도 사상을 조정하면 외부 스키마를 그대로 유지할 수 있음.
③ 내부 스키마를 수정하더라도 개념 스키마에 영향을 미치지 않는다. → ❌
- 내부 스키마(물리적 저장 구조)를 수정하면 개념 스키마에도 영향을 줄 수 있음.
- 예를 들어, 테이블의 인덱스나 저장 구조가 변경되면 개념 스키마가 이에 맞게 조정될 수 있음.
- 따라서 내부 스키마 수정이 개념 스키마에 영향을 미치지 않는다는 주장은 틀림
④ 개념 스키마를 수정하더라도 외부 스키마에 영향을 미치지 않는다. → ✅
- 논리적 독립성의 정의 그대로임.
- 즉, 개념 스키마가 바뀌어도 외부 스키마를 조정하여 사용자 인터페이스는 그대로 유지할 수 있음.
6.참조무결성규칙에대한설명으로적절하지않은것은?
①릴레이션은참조할수없는외래키값을가져서는안된다.
②참조하는릴레이션과참조되는릴레이션은반드시서로다른 릴레이션이되어야하는것은아니다.
③데이터형식을통해유형을제한하거나CHECK제약조건및 규칙을통해형식을제한한다.
④키값이변경되면해당키값에대한모든참조가데이터베이스 전체에서일관되게변경되고유지되어야한다.
개념설명
① 릴레이션은 참조할 수 없는 외래키 값을 가져서는 안 된다. → ✅
- 외래키(Foreign Key)는 반드시 기본키(Primary Key) 값을 참조해야 함.
- 즉, 존재하지 않는 기본키를 참조하는 외래키 값은 가질 수 없음.
-- 올바른 참조 (학생 테이블이 학과 테이블의 학과번호를 참조)
CREATE TABLE 학과 (
학과번호 INT PRIMARY KEY,
학과명 VARCHAR(50)
);
CREATE TABLE 학생 (
학번 INT PRIMARY KEY,
이름 VARCHAR(50),
학과번호 INT,
FOREIGN KEY (학과번호) REFERENCES 학과(학과번호)
);
② 참조하는 릴레이션과 참조되는 릴레이션은 반드시 서로 다른 릴레이션이 되어야 하는 것은 아니다. → ✅ 맞음
- 같은 테이블 내에서 자기 자신을 참조하는 자기 참조(Self-Referencing) 무결성도 가능함
CREATE TABLE 직원 (
직원번호 INT PRIMARY KEY,
이름 VARCHAR(50),
상사번호 INT,
FOREIGN KEY (상사번호) REFERENCES 직원(직원번호)
);
③ 데이터 형식을 통해 유형을 제한하거나 CHECK 제약조건 및 규칙을 통해 형식을 제한한다. → ❌ 틀림 (정답!)
- CHECK 제약조건이나 데이터 형식은 참조 무결성을 보장하는 방법이 아님.
- 참조 무결성은 FOREIGN KEY 제약조건을 사용하여 보장해야 함.
- CHECK는 특정 데이터 값의 범위를 제한하는 역할을 하지만, 외래키 무결성을 직접적으로 보장하지 않음!
CREATE TABLE 학생 (
학번 INT PRIMARY KEY,
학과번호 INT CHECK (학과번호 > 0) -- ❌ 참조 무결성 보장이 안됨!
);CREATE TABLE 학생 (
학번 INT PRIMARY KEY,
학과번호 INT,
FOREIGN KEY (학과번호) REFERENCES 학과(학과번호) -- ✅ 참조 무결성 보장
);
④ 키 값이 변경되면 해당 키 값에 대한 모든 참조가 데이터베이스 전체에서 일관되게 변경되고 유지되어야 한다. → ✅
- 기본키 값이 변경될 경우, 이를 참조하는 외래키 값도 ON UPDATE CASCADE 옵션을 통해 자동으로 변경 가능.
CREATE TABLE 학과 (
학과번호 INT PRIMARY KEY,
학과명 VARCHAR(50)
);
CREATE TABLE 학생 (
학번 INT PRIMARY KEY,
이름 VARCHAR(50),
학과번호 INT,
FOREIGN KEY (학과번호) REFERENCES 학과(학과번호) ON UPDATE CASCADE
);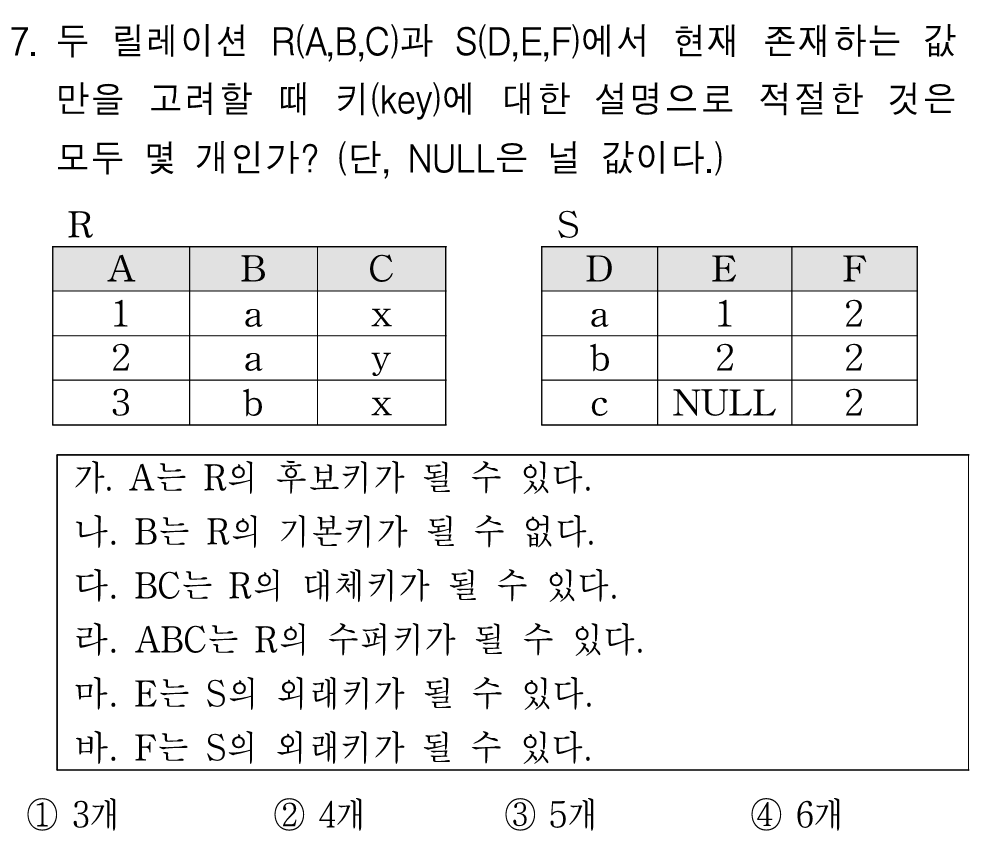
정답:
② 4개
개념설명
주어진 릴레이션 R(A,B,C) 와 S(D,E,F) 에 대해 키(key)에 대한 설명이 적절한 것의 개수를 찾는 문제다.
- 기본키(Primary Key): 테이블에서 각 행을 유일하게 식별할 수 있는 속성(중복 X, NULL X)
- 후보키(Candidate Key): 기본키로 사용할 수 있는 속성(유일성 + 최소성 만족)
- 대체키(Alternate Key): 후보키 중 기본키로 선택되지 않은 것
- 수퍼키(Super Key): 유일성을 가지지만 최소성을 만족하지 않는 키
- 외래키(Foreign Key): 다른 테이블의 기본키를 참조하는 속성
R(A,B,C)에서의 키 분석
가. A는 R의 후보키가 될 수 있다. → ✅
- A 값이 **(1, 2, 3)**으로 중복이 없으므로 유일성을 만족함.
- A 하나만으로 R의 모든 행을 식별 가능하므로 후보키가 될 수 있음. ✅
나. B는 R의 기본키가 될 수 없다. → ✅
- B 값이 **(a, a, b)**로 중복이 발생하므로 기본키가 될 수 없음. ✅
다. BC는 R의 대체키가 될 수 있다. → ❌
- B와 C의 조합을 보면 **(a, x), (a, y), (b, x)**로 유일성을 만족함.
- 하지만 A가 후보키이므로, BC는 후보키가 될 필요가 없음.
- 즉, BC는 대체키가 될 수 없으며, 틀린 설명. ❌
라. ABC는 R의 수퍼키가 될 수 있다. → ✅
- A가 이미 후보키이므로 A가 포함된 모든 속성 집합은 수퍼키가 됨.
- ABC는 A를 포함하므로 반드시 수퍼키가 됨. ✅
S(D,E,F)에서의 키 분석
마. E는 S의 외래키가 될 수 있다. → ❌
- E의 값이 **(1, 2, NULL)**이므로 NULL 값이 포함됨.
- 외래키는 NULL 값을 가질 수 없음.
- 따라서 E는 외래키가 될 수 없음. ❌
바. F는 S의 외래키가 될 수 있다. → ✅
- F 값이 **(2, 2, 2)**로 중복은 있지만, 외래키는 중복을 허용함.
- F가 다른 테이블의 기본키를 참조한다고 가정하면 외래키가 될 수 있음. ✅

정답:
①
개념설명
📌 문제 분석
이 문제는 "데이터베이스" 책을 100번 고객이 주문한 날짜(주문일)를 구하는 적절한 관계대수식을 찾는 문제.
즉, 고객번호가 100번이고, 주문한 책 제목이 '데이터베이스'인 경우의 주문일을 추출해야 함.
관계대수식을 올바르게 작성하려면 다음을 고려해야 함
- 고객(고객번호, 이름)
- 책(책번호, 제목)
- 주문(고객번호, 책번호, 주문일)
➡ 따라서 고객, 책, 주문 세 개의 릴레이션을 자연 조인(⋈)하여 조건을 만족하는 데이터를 추출해야 함.
📌 각 선택지 검토
1️⃣ ①

🚨 틀린 이유:
- 잘못된 논리 연산자(∨, OR) 사용!
- 제목 = '데이터베이스' 또는 고객번호 = 100 이므로,
- 100번 고객이 주문한 것 + '데이터베이스' 책을 주문한 모든 고객을 포함하게 됨.
- 즉, 100번 고객이 아닌 사람이 주문한 '데이터베이스' 책도 포함될 가능성이 있음.
- 정확한 조건은 제목 = '데이터베이스' AND 고객번호 = 100이어야 함.
- 정답: ①이 적절하지 않음. ✅
2️⃣ ②

✅ 맞음:
- 고객번호 = 100인 고객을 먼저 필터링하고,
- 주문과 조인한 후,
- 제목 = '데이터베이스'인 책을 필터링
- 최종적으로 주문일을 선택(Projection)
➡ 올바른 방식임.
3️⃣ ③

✅ 맞음:
- ②번과 동일한 방식으로 수행됨.
- 고객번호 = 100을 먼저 필터링 → 주문 조인 → 제목 = '데이터베이스' 책 필터링
➡ 올바른 방식임.
4️⃣ ④

✅ 맞음:
- 제목 = '데이터베이스' AND 고객번호 = 100 조건을 올바르게 적용
➡ 올바른 방식임.
📌 최종 정답: ① ✅
➡ ∨ (OR) 조건을 사용하여 100번 고객이 아닌 사람이 주문한 '데이터베이스' 책도 포함될 가능성이 있어 부적절함

정답:
①
개념설명
이 문제는 릴레이션 RR과 SS의 자연조인(⋈N\bowtie_N)과 동등하지 않은 관계대수식을 찾는 문제다.
- 자연조인(⋈N\bowtie_N): 두 릴레이션에서 공통 속성을 기준으로 조인하는 연산
- 일반 조인(⋈\bowtie): 모든 경우를 고려한 조인 (공통 속성을 기준으로 하지 않을 수도 있음)
➡ 즉, R⋈NSR \bowtie_N S와 결과가 다른 식을 찾아야 함.
각 선택지 검토
① S⋈N(S⋈R)S \bowtie_N (S \bowtie R) → ❌
- S⋈RS \bowtie R: S와 R을 일반 조인하면, 공통 속성이 있는 경우 모든 가능한 조합이 생성됨.
- S⋈N(결과)S \bowtie_N \text{(결과)}: 다시 S와 자연조인을 하면, S가 두 번 조인되는 형태가 되어 의미가 달라짐.
- 따라서 R⋈NSR \bowtie_N S와 다른 결과가 나올 수 있음
② (S⋈R)⋈NR(S \bowtie R) \bowtie_N R → ✅
- 먼저 S⋈RS \bowtie R: 일반 조인을 수행한 후,
- ⋈NR\bowtie_N R: 다시 자연조인을 수행함.
- 결국 R⋈NSR \bowtie_N S와 동일한 결과를 얻을 수 있음.
➡ R⋈NSR \bowtie_N S와 동등한 식 ✅
③ R⋈N(S⋈R)R \bowtie_N (S \bowtie R) → ✅
- **S⋈RS \bowtie R**을 먼저 수행한 후,
- **R⋈N(결과)R \bowtie_N \text{(결과)}**로 자연조인을 수행함.
- 기존 자연조인의 형태를 유지하므로 동등한 결과를 얻을 가능성이 높음.
➡ R⋈NSR \bowtie_N S와 동등한 식 ✅
④ (R⋈S)⋈NS(R \bowtie S) \bowtie_N S → ✅
- R⋈SR \bowtie S: 일반 조인을 수행한 후,
- ⋈NS\bowtie_N S: 다시 자연조인을 수행함.
- R⋈NSR \bowtie_N S와 동등한 결과를 얻을 가능성이 높음.
➡ R⋈NSR \bowtie_N S와 동등한 식 ✅

정답:
③ 복합 연산인 디비전은 기본 연산인 셀렉트, 차집합, 카티션 프로덕트로 대체할 수 있다.
개념설명
이 문제는 관계대수(Relational Algebra) 연산자에 대한 설명 중 적절하지 않은 것을 찾는 문제다.
관계대수 연산자는 기본 연산자(Select, Project, Join, Cartesian Product, Union, Set Difference 등)와
복합 연산자(Division, Outer Join 등)로 나뉨
각 선택지 검토
① 릴레이션 R에 셀렉트(select) 연산을 수행한 결과로 얻은 릴레이션의 차수는 R의 차수와 같다. → ✅
- 셀렉트(σ, Selection) 연산은 튜플(행)을 선택하는 연산이므로,
- 릴레이션의 "차수(속성 개수, Column 개수)"는 변하지 않고, 카디널리티(튜플 개수, Row 개수)만 줄어듦
② 차집합과 디비전(division)은 교환법칙과 결합법칙이 성립하지 않는다. → ✅
- 차집합(−, Difference) 연산
- A - B ≠ B - A → 교환법칙(X)
- (A - B) - C ≠ A - (B - C) → 결합법칙(X)
- 디비전(÷, Division) 연산
- A ÷ B 연산은 A에 있는 값 중 B에 해당하는 값만 남기는 연산이므로,
- 디비전은 교환법칙과 결합법칙이 성립하지 않음.
➡ 적절한 설명
③ 복합 연산인 디비전은 기본 연산인 셀렉트, 차집합, 카티션 프로덕트로 대체할 수 있다. → ❌
- 디비전(÷) 연산은 기본 연산자로 완전히 대체할 수 없음.
- 디비전은 특정 속성을 기준으로 나누는 연산이므로,
- 셀렉트(σ), 차집합(−), 카티션 프로덕트(×)만으로는 정확하게 구현할 수 없음.
- 디비전은 보통 "투영(π, Projection), 카티션 프로덕트(×), 차집합(−), 셀렉트(σ)" 등을 복합적으로 사용해야 구현 가능함.
④ 카티션 프로덕트와 외부 합집합(outer union)은 릴레이션이 합병 가능(union compatible)하지 않아도 연산이 가능하다. → ✅
- 카티션 프로덕트(×)
- 두 릴레이션이 속성 개수(차수)가 달라도 연산이 가능함.
- 외부 합집합(Outer Union, ⊍)
- 두 릴레이션이 완전히 동일한 속성을 가지지 않아도 연산 가능 (NULL을 활용하여 보완).
- 두 릴레이션이 완전히 동일한 속성을 가지지 않아도 연산 가능 (NULL을 활용하여 보완).